

Written by Todd Hunter and Henry Lindsay-Smith
Introduction
The rapid evolution of AI is fundamentally transforming how organisations leverage their data, demanding increasingly sophisticated yet simplified methods for data ingestion and integration. As data volumes explode and diversify across structured, unstructured, batch, and real-time streams, the challenge of unifying these disparate sources into a cohesive, AI-ready foundation has never been greater. It is against this backdrop that Snowflake has introduced a pivotal new offering designed to meet these modern data demands head-on: Snowflake Openflow. This eagerly anticipated service promises to revolutionise data movement, streamlining complex pipelines and empowering enterprises to unlock the full potential of their data for the AI era.
What we know?
Snowflake announced its definitive agreement to acquire Datavolo on November 20, 2024. The acquisition was intended to significantly enhance Snowflake's AI Data Cloud capabilities by simplifying data engineering and enabling easier integration of diverse enterprise data, especially unstructured data, for AI and machine learning. Snowflake’s stated goal is to use Datavolo's technology to form the basis of an open and extensible connectivity platform. This platform aims to provide a unified and streamlined way to connect any data source to any destination, supporting Snowflake's commitment to open standards and interoperability for data integration workloads, particularly in the initial "bronze layer" of the data lifecycle. We now know that Snowflake Openflow, which has appeared in Snowflake's documentation and is now generally available, built on Datavolo’s technology that connects various data sources and destinations, supporting diverse data types and is deployable in a customer's own cloud for complete control.
Datavolo, founded in 2023, was a company focused on accelerating the creation, management, and observability of multimodal data pipelines tailored for enterprise AI applications. Their core mission was to help businesses efficiently capture, process, and utilise all forms of data—including crucial unstructured files like documents, images, and logs—to power Large Language Models (LLMs) and other AI solutions. The company aimed to replace complex, custom-coded data integration with fast, flexible, and reusable pipelines, thereby simplifying access to varied data sources.
Datavolo's platform was built using Apache NiFi technology. The company was co-founded by Joe Witt, who served as CEO, and Luke Roquet, who was the COO. Both Witt and Roquet were also original creators of the Apache NiFi project.
Lastly, data ingestion, especially in a real time manner, is always a problem. Typical approaches either require the use of multiple services, undertaking labour-intensive custom builds, managing operationally intensive open source deployments or facing cost-prohibitive procurement of dedicated tools. In short the environment is ripe for some Snowflake led disruption.
Apache NiFi: Why is it interesting - from Hadoop Workhorse to the comeback kid as an AI Data Mover
Apache NiFi, an open-source data flow automation tool, may be due a resurgence, notably highlighted by Snowflake's acquisition of Datavolo, a NiFi-based solution. This positions NiFi, once pivotal in the Hadoop ecosystem, as a key technology for the data-intensive demands of Artificial Intelligence (AI). For those of you who weren’t involved in technology in the Hadoop era, you might well be asking “what is this NiFi thing?”
What is Apache NiFi?
Apache NiFi is an open-source data integration platform designed to automate the flow of data between disparate systems. Built on a flow-based programming model, NiFi enables organisations to ingest, transform, and route data in real time or batch modes, supporting a wide range of use cases from streaming and batch-data processing, preparing data for AI systems, to enterprise data lake ingestion. Its core strength lies in its ability to handle data from diverse sources—structured, unstructured, or streaming—while providing fine-grained control over data pipelines.
It offers a visual, flow-based programming paradigm where users design data pipelines via a web UI using configurable "processors." Key technical capabilities include:
Visual Flow Design: Enables construction and management of data routing, transformation, and mediation logic through a drag-and-drop interface.
Data Provenance: Provides comprehensive, real-time tracking of data lineage and chain of custody for every piece of data (FlowFile) flowing through the system.
Extensibility: Features a vast library of controllers and processors (just check the documentation!) for diverse sources, sinks, and operations, with the ability to develop custom processors (now including Python in NiFi 2.0, in addition to Java).
Scalability and Reliability: Designed for clustering, offering horizontal scalability, guaranteed data delivery, back-pressure mechanisms, and data buffering .NiFi’s write-ahead log and content repository ensure data is not lost during system failures, with failover mechanisms to maintain continuity.
Data Source Agnosticism: NiFi supports a wide range of protocols (e.g., HTTP, FTP, Kafka) and data formats (e.g., JSON, CSV, Avro), enabling integration with virtually any system.
Real-Time and Batch Processing: NiFi handles streaming data for low-latency use cases and batch data for high-throughput scenarios, with configurable prioritisation to balance performance.
Security: NiFi incorporates robust security features, including two-way SSL authentication, data encryption, and role-based access control (RBAC).
Extensibility: Developers can create custom processors or extensions, tailoring NiFi to specific business requirements.
Key Features
These are Openflow’s key features:
Open and extensible: An extensible managed service that’s powered by Apache NiFi, enabling you to build and extend processors from any data source to any destination.
Unified data integration platform: Openflow enables data engineers to handle complex, bi-directional ETL processes through a fully managed service that can be deployed inside customers’ own VPC in the cloud or on-premises.
Enterprise ready: Openflow offers out-of-the box security, compliance, and observability and maintainability hooks for data integration.
High speed ingestion of all types of data: One unified platform that lets you handle structured and unstructured data, in both batch and streaming modes from your data source to Snowflake at virtually any scale.
Continuous ingestion of multimodal data for AI processing: Near real-time unstructured data ingestion, so you can immediately ‘chat with your data’ coming from sources such as Sharepoint, Google Drive, and so on.
Based on Nifi, Openflow can simplify data ingestion.
For instance, as the example flow below shows, built in our NiFi sandpit, NiFi can easily connect to the Binance websocket to capture a stream of Bitcoin trades and price data for analytic datalakes. The platform receives JSON objects for each trade, and a MergeRecord flow aggregates these messages. Once a sufficient number is collected, it transforms them and writes the data into a single Parquet file.
A key advantage of NiFi is the ease with which additional flows can be added to process this data further and send it to various destinations, accommodating diverse requirements for the same data stream. NiFi manages the complexity of managing these flows of messages and provides easy ways to collect streams into batches. (Note that the example below is hard in many other tools)
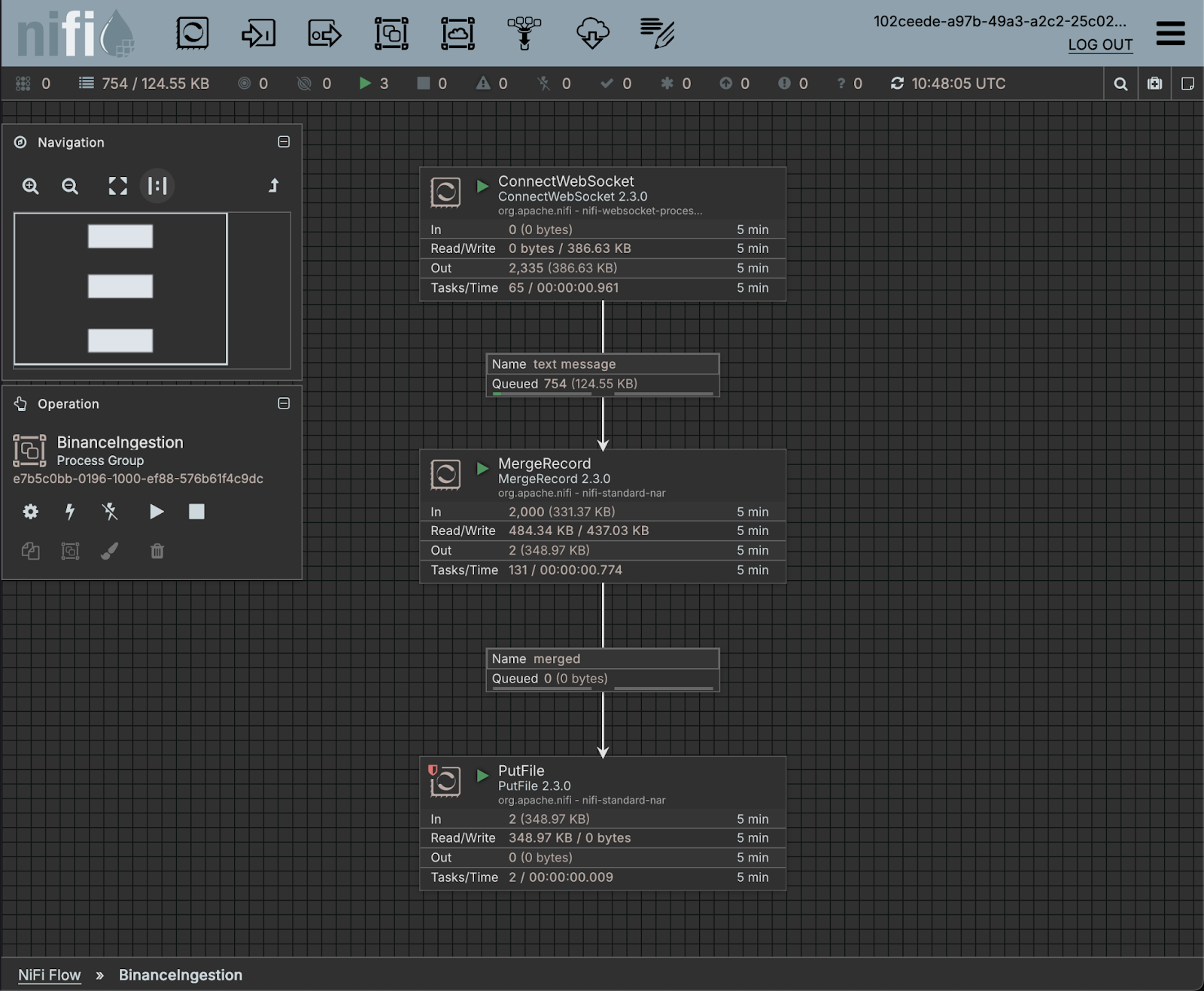
Overall our opinion is that, despite not being a widely adopted data integration tool, Apache NiFi packaged as Openflow offers compelling advantages over existing popular tooling. This makes it an attractive choice for organisations that are navigating complex data ecosystems.
Its flexibility in handling diverse data sources, formats, and protocols, and the ability to process both real-time and batch data, makes NiFi a versatile solution for modern use cases where organisations are dealing with a vast array of different data sources, data types and protocols.
Unlike proprietary tools that can lead to vendor lock-in or require significant custom coding, Openflow offers greater flexibility. Its foundation on open-source technology reduces the risks associated with vendor-specific dependencies, providing organisations with more control over their data integration pipelines. Openflow has a no-code, drag-and-drop interface which means both technical and business users are able to design and manage data flows efficiently, and quickly respond to the changing needs of the organisation. Openflow’s offering further enhances NiFi’s appeal by addressing the typical open-source challenges of managing infrastructure, optimising performance, and seamless integration with its cloud database.
Out of the box, Snowflake’s Openflow supplies connectors to many common business applications. For example, Sharepoint, Slack, and GoogleDrive. As an additional benefit of the deep integration with Snowflake, as files from these services are ingested into Snowflake, the data is prepared for further use with Cortex Search enabling RAG applications. There are also connectors which offer replication from MySQL, Postgres and other databases, as well as the ability to connect and consume Kafka messages.
All of these features mean the time could be ripe for the comeback of Apache NiFi!
Questions we have….
With all things being equal we have many questions about the gap Openflow will fill and when we will be recommending it to our clients. Certainly a reliable, easy to use and functional multi modal ingestion capability can only be a benefit for the platform that ‘Just Works’.
The non exhaustive list of questions that we are looking into includes:
Is this a competitor with Fivetran or augmenting tools such as this?
How do the costs compare to Fivetran? Or another open source solution like Airbyte?
Does it easily support Snowpipe streaming and therefore mean we can access the blistering speed and low cost of this ingestion mechanism without needing kafka?
How does the open source model work with regards to new connectors and leveraging the Apache NiFi eco system?
Managed complexity, Snowflake looks after the hard part, you focus on bringing your data but how will this work? And assuming it eventually uses Snowpark container services how much will this cost?
How is data pipeline DevOps and versioning handled?
Beyond ingestion we see enhancements to NiFi around AI and LLMs in particular and this has us wondering what use cases can they drive. We see plenty in the documentation around chunking, embedding and passing text to LLMs to generate responses. Given the nature of NiFi to be able to easily stream or process batches using the same flows we are wondering about the possibilities of scalable and distributed Generative/Agentic workflows that could be built with Nifi.
Lastly - We are proud to be supporting Snowflake as a launch partner and are grateful to have had early access to Openflow.
We’ll be publishing a follow up once we’ve dug under the hood a bit more.